A quick tour through the most popular Neural Net architecture
Have you ever thought about what happens when you read a book? Unless you have a unique ability, you don’t process and memorize every single word and special character, right? What happens is that we represent events and characters to build our understanding of the story. We do this with a selective memorization that allows us to keep the most relevant pieces of information without needing to accumulate each minor detail.
This is exactly what Hochreiter and Schmidhuber were looking for when they created the Long Short Term Memory (LSTM) model in 1997. LSTMs are types of Recurrent Neural Networks that emulate a selective memory approach, allowing them to store relevant information about the past in order to optimize a task. This impressive architecture ruled the sequential data landscape for over two decades and drove huge progress towards the way we understand different disciplines today. Unlike human memory, however, LSTMs can struggle when dealing with long-range contexts, as is the case with human language.
This limitation was particularly evident in language research that tried to move from keyword-based to more linguistic approaches in tasks like information searching, document classification, or question-answering. The nuances of human language were just too many for the Natural Language Processing discipline to keep up.
Natural Language Processing (NLP) is a field of Artificial Intelligence that gives the machines the ability to read, understand, and derive meaning from human languages. It represents the automatic handling of natural human language like speech or text, and, because, as humans, we excel at understanding our language, we tend to underestimate how hard it is for machines to do it.
Despite this,things have significantly changed in past years, and, although far from new, NLP is living a new age thanks to the invention of Transformers.
Transformers represent new architectures of Artificial Neural Networks (ANN) that generalize to many NLP tasks with incredible results.
Transformers have improved the performance of language models in a substantial way, significantly extending the model’s contextual processing. Interested in seeing how they perform? You can test Transformers here and here.
The road to Transformers
Before getting to Transformers, let’s start by understanding what an Artificial Neural Network (ANN) is.
ANNs are computing systems composed of neurons, where each neuron individually performs only a simple computation.
The power of an ANN comes from the complexity of the connections these neurons can form. ANNs accept input variables as information, weigh variables as knowledge, and output a prediction. Every ANN works this way.
The concept is far from new, since the first ANN (the Perceptron) was created in 1958. At the beginning, ANNs were built and used to solve basic tasks, but they rapidly evolved, becoming complex mechanisms able to solve challenges in areas like Computer Vision and Natural Language Processing.

ANNs architectures were expanded and improved in order to fit the complexity of the data we started gathering; Convolutional Neural Networks (CNNs) were designed to process spatial data like images, while Recurrent Neural Networks (RNNs) and Long Short Term Memories (LSTMs) were built to process sequential data like text.
But it wasn’t until just recently that something changed the way we conceived most of our challenges. Introduced in 2017, Transformers rapidly showed effective results at modelling data with long-range dependencies. Originally thought to solve NLP tasks, the application of Transformers has expanded, reaching incredible accomplishments in many disciplines.
Healthcare
Many of the world’s greatest challenges, such as developing treatments for diseases or finding enzymes that break down industrial waste, are fundamentally tied to proteins and the role they play. A protein’s shape is closely linked to its function, and the ability to predict this structure unlocks a greater understanding of what it does and how it works. In a major scientific advance, DeepMind’s AlphaFold system has been recognised as a solution to this grand challenge.
Self-driving cars
Tesla’s strategy is built around its Artificial Neural Networks. Unlike many self-driving car companies, Tesla does not use lidar, a more expensive sensor that can see the world in 3D. It relies instead on interpreting scenes by using neural network algorithms to parse input from its cameras and radar.
Art generation
DALL·E parses text prompts and then responds not with words, but in pictures. It has been specifically trained to generate images from text descriptions, using a dataset of text-image pairs. The amazing thing is that DALL·E can do more than just paint a pretty picture from a caption: It can also, in a sense, answer questions visually. DALL·E is often able to solve matrices that involve continuing simple patterns or basic geometric reasoning.

These examples are impressive, and, although they seem unrelated, they have one common factor: They all use Transformers architectures.
Now let’s see how Transformers work.
The anatomy of Transformers
It’s usually helpful to visualize things when trying to understand them. Let’s see what Transformers look like:
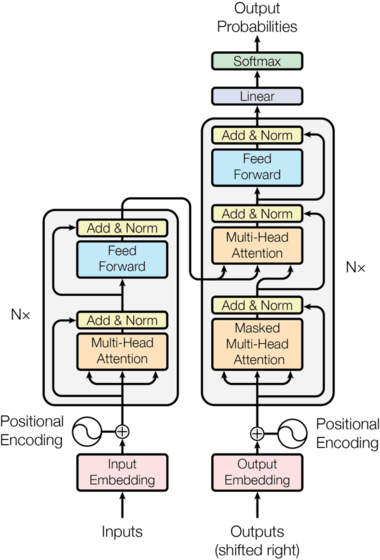
Too much information, right? Let’s start with the basics. In very simple terms, a Transformer’s architecture consists of encoder and decoder components. The encoder receives an input (e.g. a sentence to be translated), processes it into a hidden representation, and passes it to the decoder, which returns an output (e.g. the translated sentence).
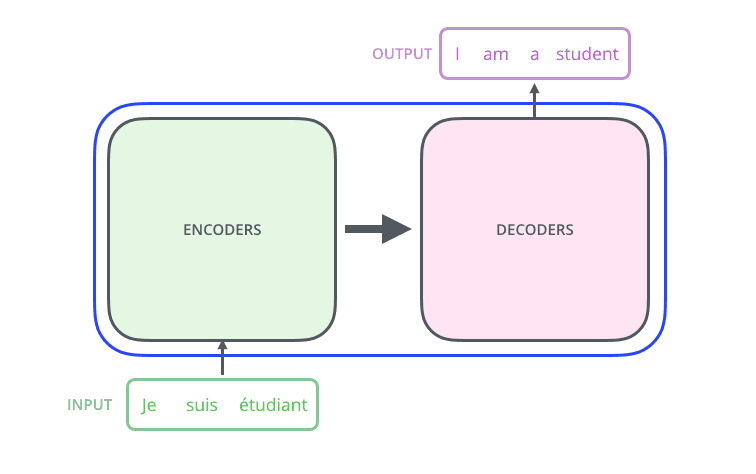
Going back to the model, we can find the encoder and decoder components as follows:
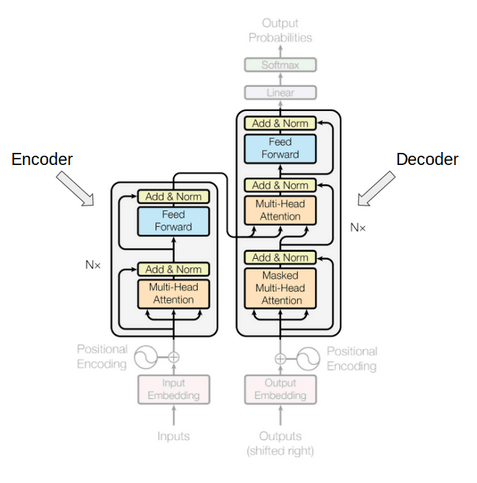
Take a look at the image above. The encoder block has one layer of a Multi-Head Attention followed by another layer of Feed Forward Neural Network. The decoder, on the other hand, has an extra Masked Multi-Head Attention. What are those “attention” layers about?
Before Transformers, ANN architectures, like RNNs, had severe memory problems. In the case of RNNs, there’s a limited scope they can remember about long-range dependencies (the words they saw a long time ago that are somehow related to the next word). That is, RNNs put too much emphasis on words being close to one another and too much emphasis on upstream context over downstream context. Reading one word at a time, RNNs need to perform multiple steps to make decisions that depend on words far away from each other, which is incredibly slow.
Self-attention fixes this problem.
Using self-attention mechanisms, Transformers can capture the context of a word from distant parts of a sentence, both before and after the appearance of that word, in order to encode valuable information. Sentences are processed as a whole, rather than word by word. This way, Transformer models avoid suffering from long dependency issues and forgetting past information.
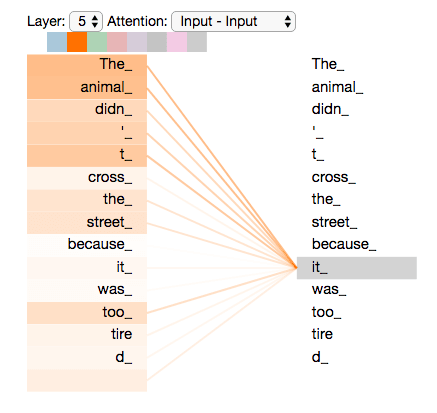
Self-attention is computed not once but multiple times in the Transformer’s architecture, in parallel and independently (aptly referred to as Multi-head Attention).
And what about performance? The sequential nature of RNNs makes it more difficult to fully take advantage of fast modern computing devices such as TPUs and GPUs, which excel at parallel and non-sequential processing. Since the Transformer architecture lends itself to parallelization, we can really boost the speed with which these models can be trained.
Transformers' successful results led to their escalation into massive models trained with absurd amounts of data, capable of performing the most diverse tasks.
Big kids on the block
What do you get when you mix Transformers with huge volumes of data? Huge advances happened in the past years after training Transformers with massive data volumes.
BERT
BERT, or Bidirectional Encoder Representations from Transformers, is one giant model designed by Google. While being conceptually simple, BERT obtains new state-of-the-art results on eleven NLP tasks, including question answering, named entity recognition and other tasks related to general language understanding.
Trained on 2.5 billion words, its design allows the model to consider the context from both the left and the right sides of each word. For example, it can understand the semantic meanings of bank in the following sentences: “Raise your oars when you get to the river bank” and “The bank is sending a new debit card.” To understand this, it uses left-to-right river and right-to-left debit card clues.
GPT
Developed by OpenAI, Generative Pre-trained Transformer (GPT) models require a small amount of input text to generate large volumes of relevant and sophisticated outputs. Unlike BERT, GPT models are unidirectional, and their main advantage is the magnitude of data they were pretrained on: GPT-3, the third-generation GPT model, was trained on 175 billion parameters, about 10 times the size of previous models. This gigantic pretrained model provides users with the ability to fine-tune NLP tasks with very little data to accomplish novel tasks, like creating articles, poetry, stories, news reports and dialogue.
MEGATRON-TURING
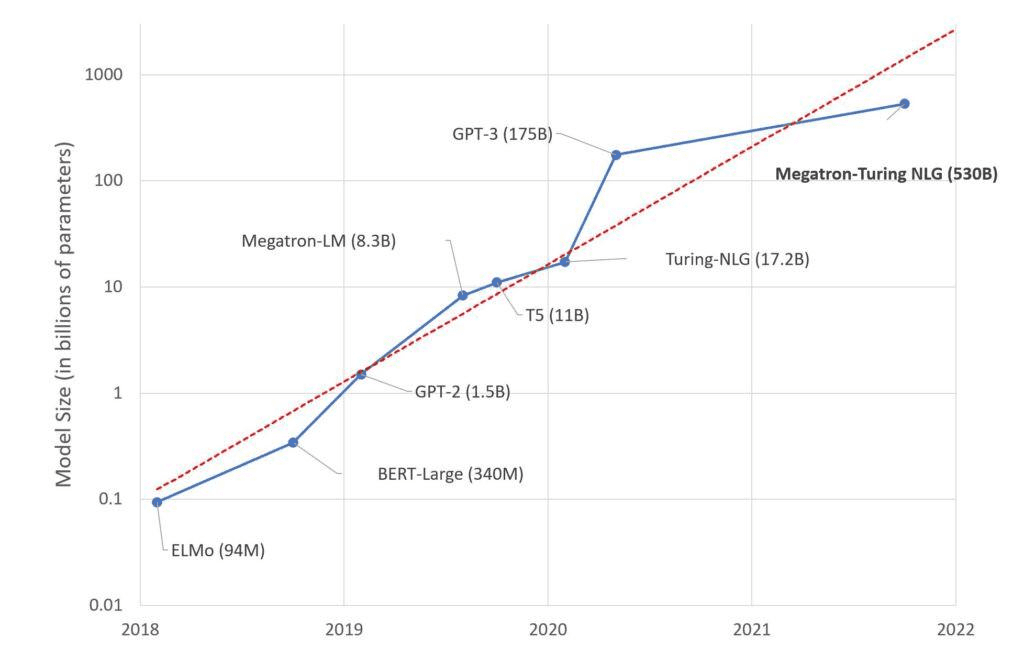
You thought GPT-3 was big? A couple of months ago, Microsoft and Nvidia released the Megatron-Turing Natural Language Generation model (MT-NLG), which is more than triple the size of GPT-3 at 530 billion parameters.
As you can imagine, getting to 530 billion parameters required quite a lot of input data and just as much computing power. The algorithm was trained using an Nvidia supercomputer made up of 4,480 GPUs and an estimated cost of over $85 million.
This massive model is skilled at tasks like completion prediction, reading comprehension, common-sense reasoning, natural language inferences, and word sense disambiguation.
What’s next?
Since Google developed Transformers, most contributions in NLP have been more related to implementation volumes rather than to architectural improvements. And there’s a reason for this: Transformers just work.
Transformers are a fascinating architecture to represent a wide variety of tasks, surprisingly versatile and robust enough to ingest incredible amounts of data. These architectures are so adaptable that we’re witnessing an explosion beyond NLP. Just this year, Vision Transformer (ViT) emerged as an alternative to Convolutional Neural Networks (CNNs), which are currently state-of-the-art models in computer vision. ViT models are outperforming CNNs in terms of computational efficiency and accuracy, achieving highly competitive performance in tasks like image classification, object detection, and semantic image segmentation.
We’re probably only in the middle of the Transformers era, as models keep getting bigger and applied to different disciplines. It’s hard to say for how long, but given this pace, Transformers will keep on building great advancements in Machine Learning for years to come.