An Introduction to Open Domain Question-Answering
Search is a crucial functionality in many applications and companies globally. Whether in manufacturing, finance, healthcare, or almost any other industry, organizations have vast internal information and document repositories.
Unfortunately, the scale of many companies’ data means that the organization and accessibility of information can become incredibly inefficient. The problem is exacerbated for language-based information. Language is a tool for people to communicate often abstract ideas and concepts. Naturally, ideas and concepts are harder for a computer to comprehend and store in a meaningful way.
Most organizations rely on a cluster of keyword-based search interfaces hosted on various ‘internal portals’ to deal with language data. If done well, this can satisfy business requirements for some of that data.
If a person knows what they’re looking for and they know the keywords and terminology of the information they need, a keyword-based search is ideal. When the keywords and terminology of the answer are unknown, keyword search is inadequate. People searching for unknown answers in large repositories of documents is a drain on productivity.
How do we minimize this problem? The answer lies with semantic search, specifically with the question-answering (QA) flavor of semantic search.
Semantic search allows us to search based on concepts and ideas rather than keywords. Given a phrase, a semantic search tool returns the most semantically similar phrases from a repository.
Question-answering takes this idea further by searching using a natural language question and returning relevant documents and specific answers. QA aims to mimic natural language as much as possible. If we asked a shop assistant “where are those tasty, freshly baked things that are not cookies but look like cookies?", we would expect directions that take us to those things. This natural form of conversation is what QA aims to reproduce.
This article will introduce the different forms of QA, the components of these ‘QA stacks’, and where we might use them.
Question Answering at a Glance
Before we dive into the details, let us paint a high-level picture of QA. First, our focus is on open-domain QA (ODQA). ODQA systems deal with questions across broad topics and cannot rely on a specific set of rules in your code. The alternative to open-domain is closed-domain, which focuses on a limited domain/scope and can often rely on explicit logic. We will not cover closed-domain QA.
For the remainder of the article, I will use ODQA and QA interchangeably. ODQA models can be split into a few subcategories.
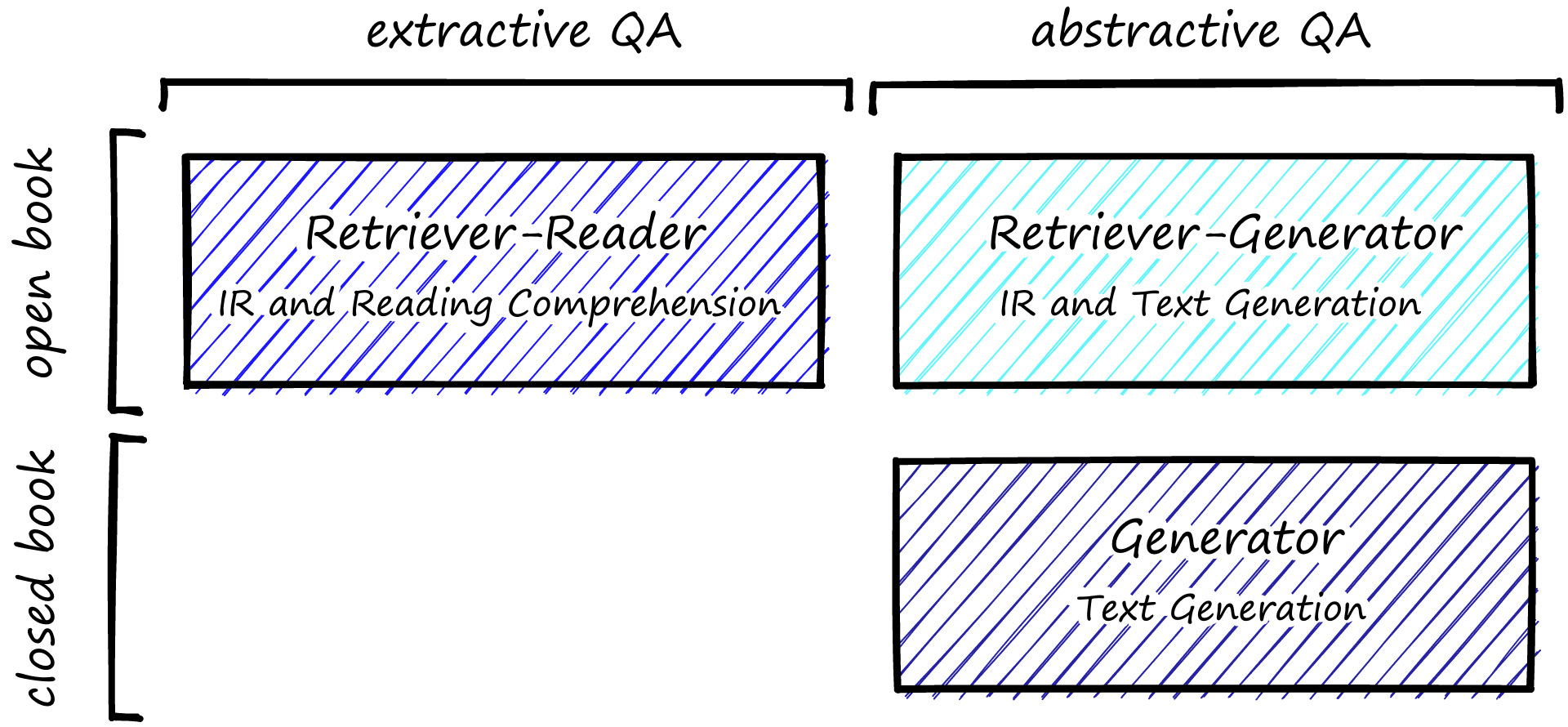
The most common form of QA is open-book extractive QA (top-left above). Here we combine an information retrieval (IR) step and a reading comprehension (RC) step.
Any open-book QA requires an IR step to retrieve relevant information from the ‘open-book’. Just as with open-book exams where students can refer to their books for information during the exam, the model can refer to an external source of information. That source of information may be internal company documents, Wikipedia, Reddit, or any other information source that is not the model itself.
The IR step retrieves relevant documents and passes them to the RC (reader) step. RC consists of extracting a succinct answer from a sentence or paragraph, typically referred to as the document or context.

The other two types of QA rely on generating answers rather than extracting them. OpenAI’s GPT models are well-known generative transformer models.
In open-book abstractive QA, the first IR step is the same as extractive QA; relevant contexts are retrieved from an external source. These contexts are passed to the text generation model (such as GPT) and used to generate (not extract) an answer.
Alternatively, we can use closed-book abstractive QA. Here there is only a text generation model and no IR step. The generator model will generate an answer based on its own internal learned representation of the world. It cannot refer to any external source of information hence the name closed-book.
Let’s dive into each of these approaches and learn where we might apply each.
Extractive QA
Extractive QA is arguably the most widely applicable form of question-answering. It allows us to ask a question and then extract an answer from a short text. For example, we have the text (or context):
Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California.
To which we could ask the question, "which team represented the AFC at Super Bowl 50?" and we should expect to return "Denver Broncos".
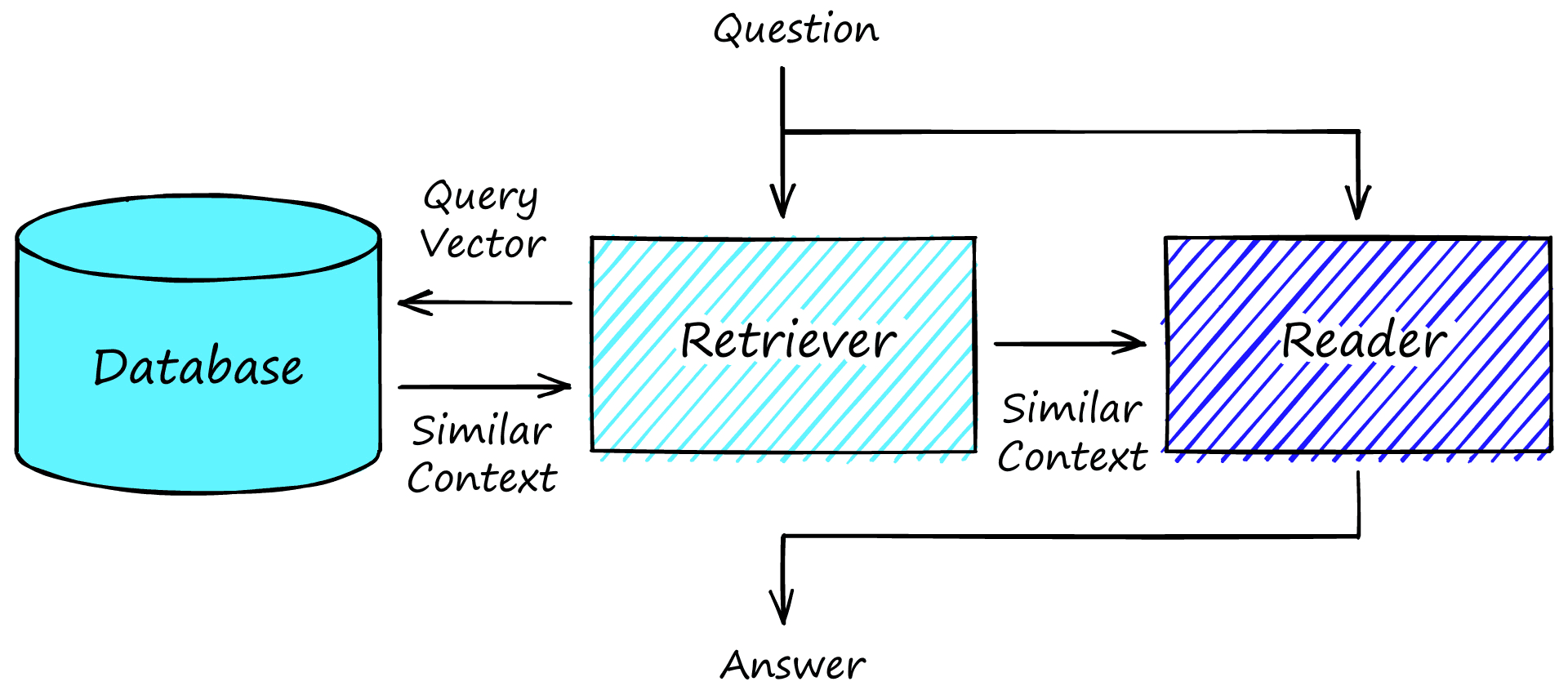
The example where we present a single context and extract an answer is reading comprehension (RC). Alone, this is not particularly useful, but we can couple it with an external data source and search through many contexts, not just one. We call this ‘open-book extractive QA’. More commonly referred to as just extractive QA. It is not a single model but actually consists of three components:
- Indexed data (document store/vector database)
- Retriever model
- Reader model
Before beginning to ask questions, open-book QA requires indexing data that our retriever model can later access. Typically this will be chunks of sentence-to-paragraph-sized text.
Let’s work through an example. First, we need data. A popular QA dataset is the Stanford Question and Answering Dataset (SQuAD). We can download this dataset using Hugging Face’s datasets library like so:
import datasets
qa = datasets.load_dataset('squad', split='validation')
qaDataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 10570
})qa[0]{'id': '56be4db0acb8001400a502ec',
'title': 'Super_Bowl_50',
'context': 'Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi\'s Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the "golden anniversary" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as "Super Bowl L"), so that the logo could prominently feature the Arabic numerals 50.',
'question': 'Which NFL team represented the AFC at Super Bowl 50?',
'answers': {'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos'],
'answer_start': [177, 177, 177]}}Here we have the context feature. It is these contexts that should be indexed in our database.
Options for the type of database vary based on the retriever model. A traditional retriever uses sparse vector retrieval with TF-IDF or BM25. These models return contexts based on the frequency of matching words between a context and the question. More word matches equate to higher relevance. Elasticsearch is the most popular database solution for this thanks to their scalable and strong keyword search capabilities.
The other option is to use dense vector retrieval with sentence vectors built by transformer models like BERT. Dense vectors have the advantage of enabling search via semantics. Searching with the meaning of a question as described in the ‘tasty, freshly baked things’ example. For this, a vector database like Pinecone or a standalone vector index like Faiss is needed.
We will try the dense vector approach. First, we encode our contexts with a QA model like multi-qa-MiniLM-L6-cos-v1 from sentence-transformers. We initialize the model with:
!pip install sentence-transformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')
modelSentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)Using the model, we encode the contexts inside our dataset object qa to create the sentence vector representations to be indexed in our vector database.
qa = qa.map(lambda x: {
'encoding': model.encode(x['context']).tolist()
}, batched=True, batch_size=32)
qa100%|██████████| 65/65 [08:57<00:00, 8.26s/ba]
Dataset({
features: ['answers', 'context', 'encoding', 'id', 'question', 'title'],
num_rows: 2067
})Now we can go ahead and store these inside a vector database. We will use Pinecone in this example (which does require a free API key). First, we initialize a connection to Pinecone, create a new index, and connect to it.
!pip install pinecone-client
import pinecone
pinecone.init(
api_key=API_KEY,
environment='YOUR_ENV' # find next to API key in console
)
# check if index already exists, if not we create it
if 'qa-index' not in pinecone.list_indexes():
pinecone.create_index(
name='qa-index',
dimension=len(qa[0]['encoding'])
)
# connect to index
index = pinecone.Index('qa-index')From there, all we need to do is upsert (upload and insert) our vectors to the Pinecone index. We do this in batches where each sample is a tuple of (id, vector).
from tqdm.auto import tqdm # progress bar
upserts = [(v['id'], v['encoding']) for v in qa]
# now upsert in chunks
for i in tqdm(range(0, len(upserts), 50)):
i_end = i + 50
if i_end > len(upserts): i_end = len(upserts)
index.upsert(vectors=upserts[i:i_end])100%|██████████| 42/42 [00:27<00:00, 1.51it/s]
Once the contexts have been indexed inside the database, we can move on to the QA process.
Given a question/query, the retriever creates a sparse/dense vector representation called a query vector. This query vector is compared against all of the already indexed context vectors in the database. The n most similar are returned.
query = "Which NFL team represented the AFC at Super Bowl 50?"
xq = model.encode([query]).tolist()xc = index.query(xq, top_k=5)
xc{'results': [{'matches': [{'id': '56be4db0acb8001400a502ec',
'score': 0.685847521,
'values': []},
...
{'id': '56bec0dd3aeaaa14008c9357',
'score': 0.520058692,
'values': []}],
'namespace': ''}]}ids = [x['id'] for x in xc['results'][0]['matches']]
contexts = qa.filter(lambda x: True if x['id'] in ids else False)
contexts['context']100%|██████████| 3/3 [00:00<00:00, 7.84ba/s]
['Super Bowl 50 was an American football game...',
'The Panthers finished the regular season with...',
'In early 2012, NFL Commissioner Roger Goodell...',
'In the United States, the game was televised...',
"Super Bowl 50 featured numerous records from..."]These most similar contexts are passed (one at a time) to the reader model alongside the original question. Given a question and context, the reader predicts the start and end positions of an answer.
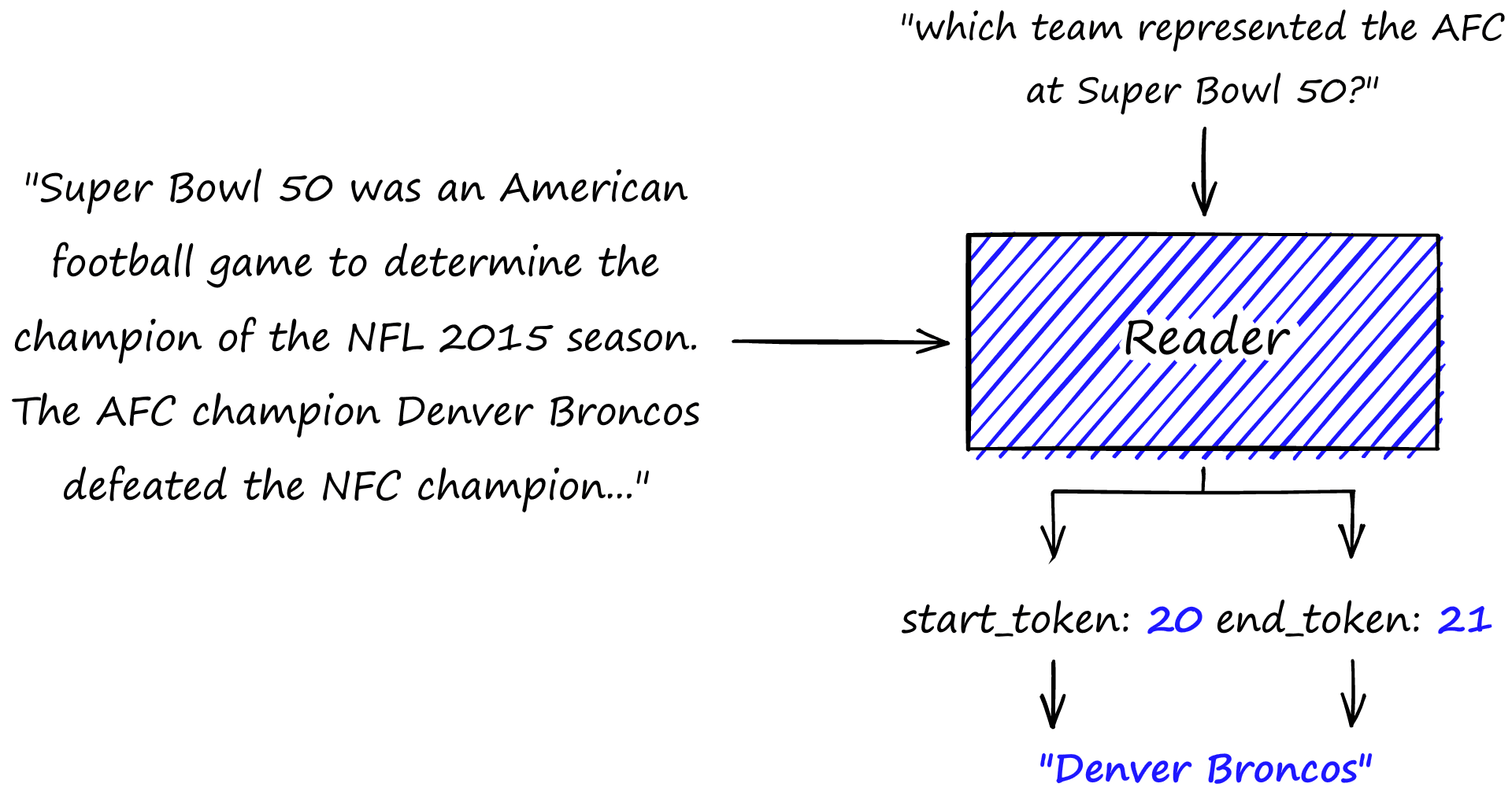
We will use the deepest/electra-base-squad2 model from HuggingFace’s transformers as our reader model. All we do is set up a 'question-answering' pipeline and pass our query and contexts to it one by one.
from transformers import pipeline
model_name = 'deepset/electra-base-squad2'
nlp = pipeline(tokenizer=model_name, model=model_name, task='question-answering')print(query)
for context in contexts['context']:
print(nlp(question=query, context=context))Which NFL team represented the AFC at Super Bowl 50?
{'score': 0.9998526573181152, 'start': 177, 'end': 191, 'answer': 'Denver Broncos'}
{'score': 6.595961963284935e-07, 'start': 525, 'end': 539, 'answer': 'Dallas Cowboys'}
{'score': 1.11751314761932e-05, 'start': 15, 'end': 93, 'answer': 'NFL Commissioner Roger Goodell stated that the league planned to make the 50th'}
{'score': 2.344028617040639e-12, 'start': 564, 'end': 579, 'answer': 'Super Bowl XXXV'}
{'score': 0.009671280160546303, 'start': 68, 'end': 74, 'answer': 'Denver'}
The reader prediction is repeated for each context. From here — if preferred — we can order the ‘answers’ using the scores output by the retriever and/or reader models.
As we can see, the model returns the correct answer of 'Denver Broncos' with a score of 0.99. Most other answers return only minuscule scores, showing that our reader model easily distinguishes between good and bad answers.
Abstractive QA
As we saw before, abstractive QA can be split into two types: open-book and closed-book. We will start with open-book as the natural continuation of the previous extractive QA pipeline.
Open Book
Being open-book abstractive QA, we can use the same database and retriever components used for extractive QA. These components work in the same way and deliver a set of contexts to our generator model, which replaces the reader from extractive QA.
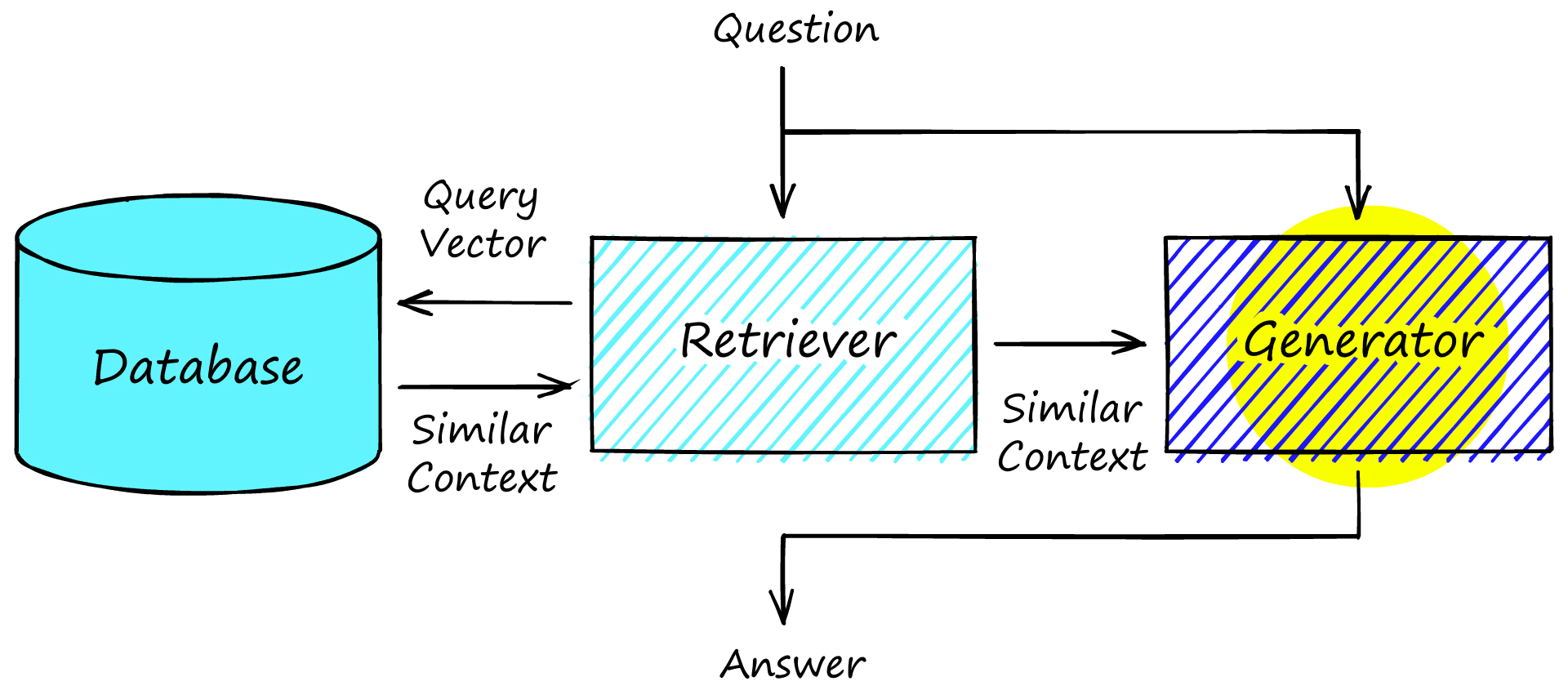
Rather than extracting answers, contexts are used as input (alongside the question) to a generative sequence-to-sequence (seq2seq) model. The model uses the question and context to generate an answer.
Large transformer models store ‘representations’ of knowledge in their parameters. By passing relevant contexts and questions into the model, we hope that the model will use the context alongside its ‘stored knowledge’ to answer more abstract questions.
The seq2seq model used is commonly BART or T5-based. We will go ahead and initialize a seq2seq pipeline using a BART model fine-tuned for abstractive QA — yjernite/bart_eli5.
from transformers import pipeline
model_name = 'yjernite/bart_eli5'
seq2seq = pipeline('text2text-generation', model=model_name, tokenizer=model_name)The question we asked before is specific. We’re looking for a short and concise answer of Denver Broncos. Abstractive QA is not ideal for these types of questions:
for context in contexts['context']:
answer = seq2seq(
f"question: {query} context: {context}",
num_beams=4,
do_sample=True,
temperature=1.5,
max_length=64
)
print(answer)[{'generated_text':
' The AFC had one of the two remaining wild card spots. So the team that won the divisional playoffs represented the AFC. It was the same as how the Buffalo Bills represented the AFC in Super Bowl 50.'}]
[{'generated_text':
' It was a wild card match, so it was decided to swap teams for the Super Bowl 50 game. The New England Patriots won that match so they were automatically guaranteed to be a part of the game. The New York Jets were a wild card selection so they were assigned a spot in the game.'}]
[{'generated_text':
" It's kind of like the difference between having a dog and a pony. A dog will give a little extra attention to you but that's it. A pony is a bit more of a nuisance but that's not a big deal."}]
[{'generated_text':
" Each team has a team coach. Which NFL team you're asking about is a different question. I'm not sure why you're assuming that the AFC is represented at Super Bowl 50. It's an entirely different thing. The AFC is represented by the AFC team that won the AFC Championship last year. Which team"}]
[{'generated_text':
" The AFC won the AFC Championship. That's the correct answer. The AFC Championship game is the final game of the season between the AFC and AFC. The AFC Championship game is the regular season of the playoffs, which are the playoffs for the teams in the AFC. The AFC Championship is the final game of the"}]
Instead, the benefit of abstractive QA comes with more ‘abstract’ questions like "Do NFL teams only care about playing at the Super Bowl?" Here, we’re almost asking for an opinion. There is unlikely to be an exact answer. Let’s see what the abstractive QA method thinks about this.
query = "Do NFL teams only care about playing at the Superbowl?"
xq = retriever.encode([query]).tolist()xc = index.query(xq, top_k=5)
ids = [x['id'] for x in xc['results'][0]['matches']]
contexts = qa.filter(lambda x: True if x['id'] in ids else False)for context in contexts['context']:
answer = seq2seq(
f"question: {query} context: {context}",
num_beams=4,
do_sample=True,
temperature=1.5,
max_length=64
)
print(answer)[{'generated_text':
' No, because it is the pinnacle of professional football. You can only get so good at being a pro team, and the Superbowl is a good example of how great they can be. Most of the teams that play in the Superbowl are teams that have had bad seasons, or are rebuilding teams, or'}]
[{'generated_text':
" I'm no expert, but I would guess that it's about how well the team is prepared. A team needs to be able to score goals. Even if the opponents have a bunch of players that can't be as good as the team, maybe the team can't score as many goals. Maybe there's"}]
[{'generated_text':
" It's not just NFL teams, it's all sports teams. They want to play at the Super Bowl. This is also why the Super Bowl is so important for the world Cup. The world cup is held every two years, the NFL is the one that takes place every four years."}]
[{'generated_text':
" I'm not sure how you can ask a question that makes no sense. They don't have a right to the Super Bowl, it's just a big event that brings thousands of people to a city. They don't care if they lose, they just care if they get a nice, big crowd to cheer"}]
[{'generated_text':
' They are paid a lot of money to be in the Superbowl. It makes them feel a lot better about being a part of it. The NFL owners are paid a lot of money to allow them to play in the Superbowl.'}]
These answers look much better than our ‘specific’ question. The returned contexts don’t include direct information about whether the teams care about being in the Super Bowl. Instead, they contain snippets of concrete NFL/Super Bowl details.
The seq2seq model combines those details and its own internal ‘knowledge’ to produce some insightful thoughts on the question:
- “No, because it is the pinnacle of professional football” — points out that teams in the Super Bowl (whether they win or not) already know they’re at the top; in a way, they’ve ‘already won’.
- “They don’t care if they lose, they just care if they get a nice, big crowd to cheer” — players are happy that they get to entertain their fans; that is, the Super Bowl is less important.
- “They are paid a lot of money to be in the Superbowl” — points out the more obvious ‘who wouldn’t want bucket loads of money?’.
There is plenty of contradiction and opinion, but that is often the case with more abstract questioning, particularly with the question we asked.
Although these results are interesting, they’re not perfect. We can tweak parameters such as temperature to increase/decrease randomness in the answers, but abstractive QA can be limited in its coherence.
Closed Book
The final architecture we will look at is closed-book abstractive QA. In reality, this is nothing more than a generative model that takes a question and relies on nothing more than its own internal knowledge. There is no retrieval step.
Although we’re dropping the retriever model, that doesn’t mean we stick with the same reader model. As we saw before, the yjernite/bart_eli5 model requires input like:
question: <our question> context: <a (hopefully) relevant context>
Without the context input, the previous model does not perform as well. This is to be expected. The seq2seq model is optimized to produce coherent answers when given both question and context. If our input is in a new, unexpected format, performance suffers:
query = "Do NFL teams only care about playing at the Super Bowl?"
seq2seq(
f"question: {query} context: unknown",
num_beams=4,
do_sample=True,
temperature=1.5,
max_length=64
)[{'generated_text': ' I have a follow-up question: Do the NFL teams only have one shot at winning the Super Bowl? Do they only have ONE shot at winning the Super Bowl?'}]The model doesn’t know the answer and flips the direction of questioning. Unfortunately, this isn’t really what we want. However, there are many alternative models we can try. The GPT models from OpenAI are well-known examples of generative transformers and can produce good results.
GPT-3, the most recent GPT from OpenAI, is locked behind an API, but there are open-source alternatives like GPT-Neo from Eleuther AI. Let’s try one of the smaller GPT-Neo models.
gen = pipeline('text-generation', model='EleutherAI/gpt-neo-125M', tokenizer='EleutherAI/gpt-neo-125M')
gen(query, max_length=32)[{'generated_text': 'Do NFL teams only care about playing at the Super Bowl?\n\nThe NFL is a great place to play, but it’s not the only place'}]Here we’re using the 'text-generation' pipeline. All we do here is generate text following a question. We do get an interesting answer which is true but doesn’t necessarily answer the question. We can try a few more questions.
gen("Where do cats come from?", max_length=32)[{'generated_text': 'Where do cats come from?\n\nCats are a group of animals that are found in the wild. They are the most common species in the wild,'}]gen("Who was the first person on the moon?", max_length=32)[{'generated_text': "Who was the first person on the moon?\n\nThe moon is the most important part of the Earth's atmosphere. It is the most important part of the"}]gen("What is the moon made of?", max_length=32)[{'generated_text': 'What is the moon made of?\n\nThe moon is a kind of material that is made of a material that is made of a material that is made of'}]We can tweak parameters to reduce the likelihood of repetition.
gen("What is the moon made of?", max_length=32, do_sample=True)[{'generated_text': 'What is the moon made of?\n\nWhat is the moon made of?\n\nThe moon is a powerful weapon, but the best example may be on'}]We do get some interesting results, although it is clear that closed-book abstractive QA is a challenging task. Larger models store more internal knowledge; thus, closed-book performance is very much tied to model size. With bigger models, we can get better results, but for consistent answers, the open-book alternatives tend to outperform the closed-book approach.
That’s it for our article on open-domain question answering (ODQA). We’ve worked through the idea behind semantic similarity and how it is applied to QA models. We explored the various components that produce these ‘QA stacks’, like vector databases, retrievers, readers, and generators. Alongside that, we’ve learned how to implement these different stacks using different tools and models. All of this should provide a strong foundation for exploring the world and opportunities of ODQA further.
Further Reading
- L. Weng, How to Build an Open-Domain Question Answering System?, GitHub Blog
- D. Khashabi, et al., UnifiedQA: Crossing Format Boundaries with a Single QA System (2020), EMNLP
- Extractive Question Answering, Hugging Face Docs