Pinecone Inference now supports llama-text-embed-2. Developed by NVIDIA on the Llama 3.2 1B architecture, it delivers remarkable retrieval quality at low latency. With fully managed, native support in Pinecone, getting started is as simple as an API call.
Key Features
- Superior retrieval quality: The model surpasses OpenAI's text-embedding-3-large across multiple benchmarks, in some cases improving accuracy by more than 20%
- Real-time queries: Predictable and consistent query speeds for responsive search with p99 latencies 12x faster than OpenAI Large
- Flexibility: Up to 2048 tokens per chunk (recommended 400-500) and support for variable dimension options (384-2048) to optimize for storage
- Multilingual: Supports 26 languages, including English, Spanish, Chinese, Hindi, Japanese, Korean, French, and German
Superior retrieval quality
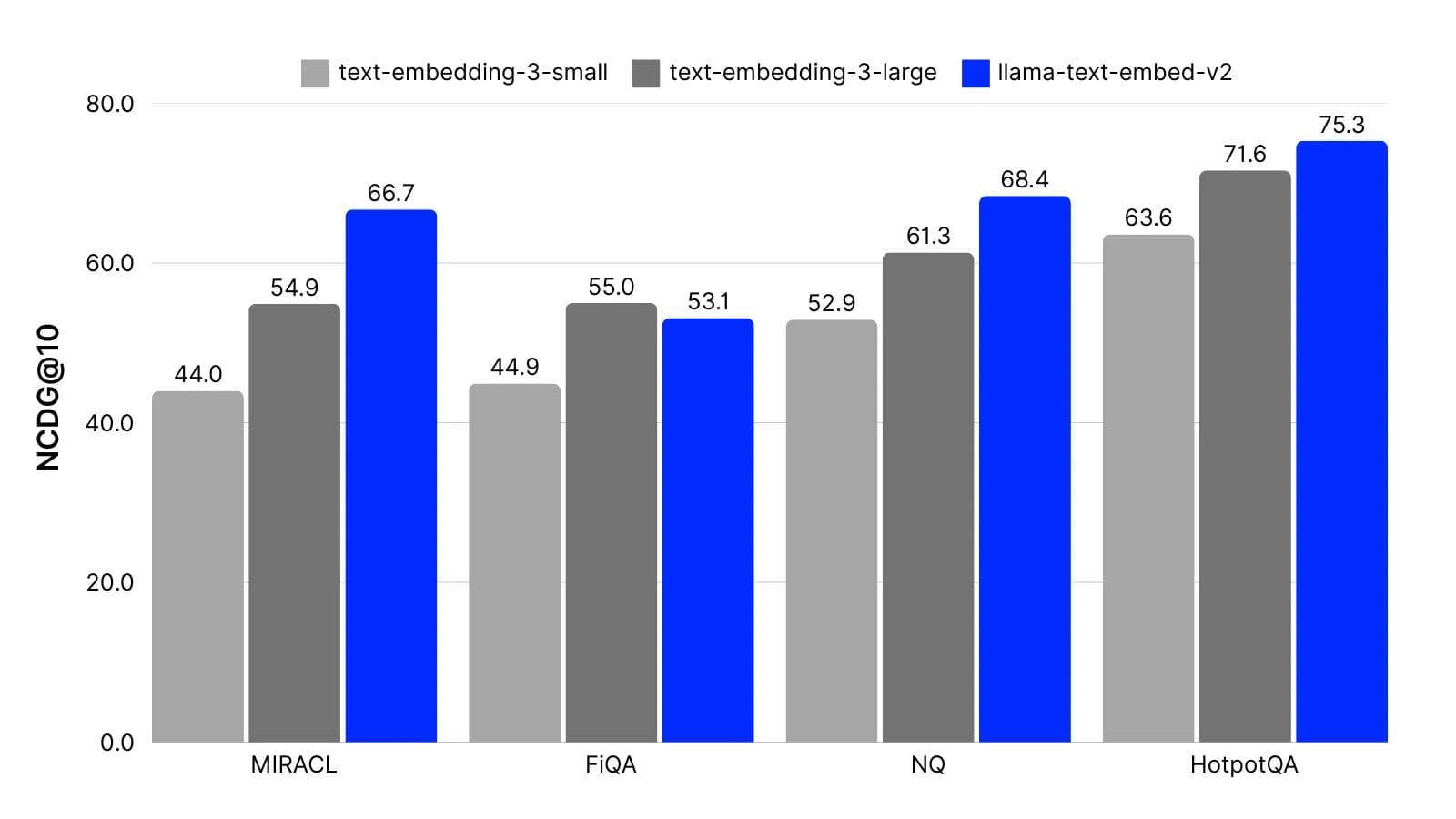
Trained explicitly for retrieval applications, llama-text-embed-v2 consistently delivers higher quality results compared to other industry-leading models. The model excels particularly in domain-specific retrieval, as demonstrated by its performance on the FiQA financial dataset where it achieves a score of 53.1, nearly matching OpenAI's large model. For general knowledge retrieval, it shows even more impressive results, outperforming OpenAI on Natural Questions (NQ) with a score of 68.4 and HotpotQA with 75.3. These benchmarks evaluate different aspects of retrieval capability—from simple fact-finding to complex multi-hop reasoning where information must be gathered from multiple sources. The model's strong performance across these tasks demonstrates its robustness required for RAG, agentic, and semantic search applications.
Real-time queries
Search speed directly impacts application performance and user satisfaction. A production-grade retrieval system is a multi-step process, combining embedding generation, vector search, and reranking—requiring a well-tuned system to ensure optimal performance.
As part of evaluating and optimizing our deployment of llama-text-embed-v2, we ran extensive latency and performance benchmarks. To simulate the use of the model for generating embeddings for queries, we conducted the following benchmark: 5 concurrent processes, each running 500 iterations of ~20-token queries across 10 loops run from GCP’s us-central1 region. The results demonstrate both faster and more consistent latencies than OpenAI’s embedding service.
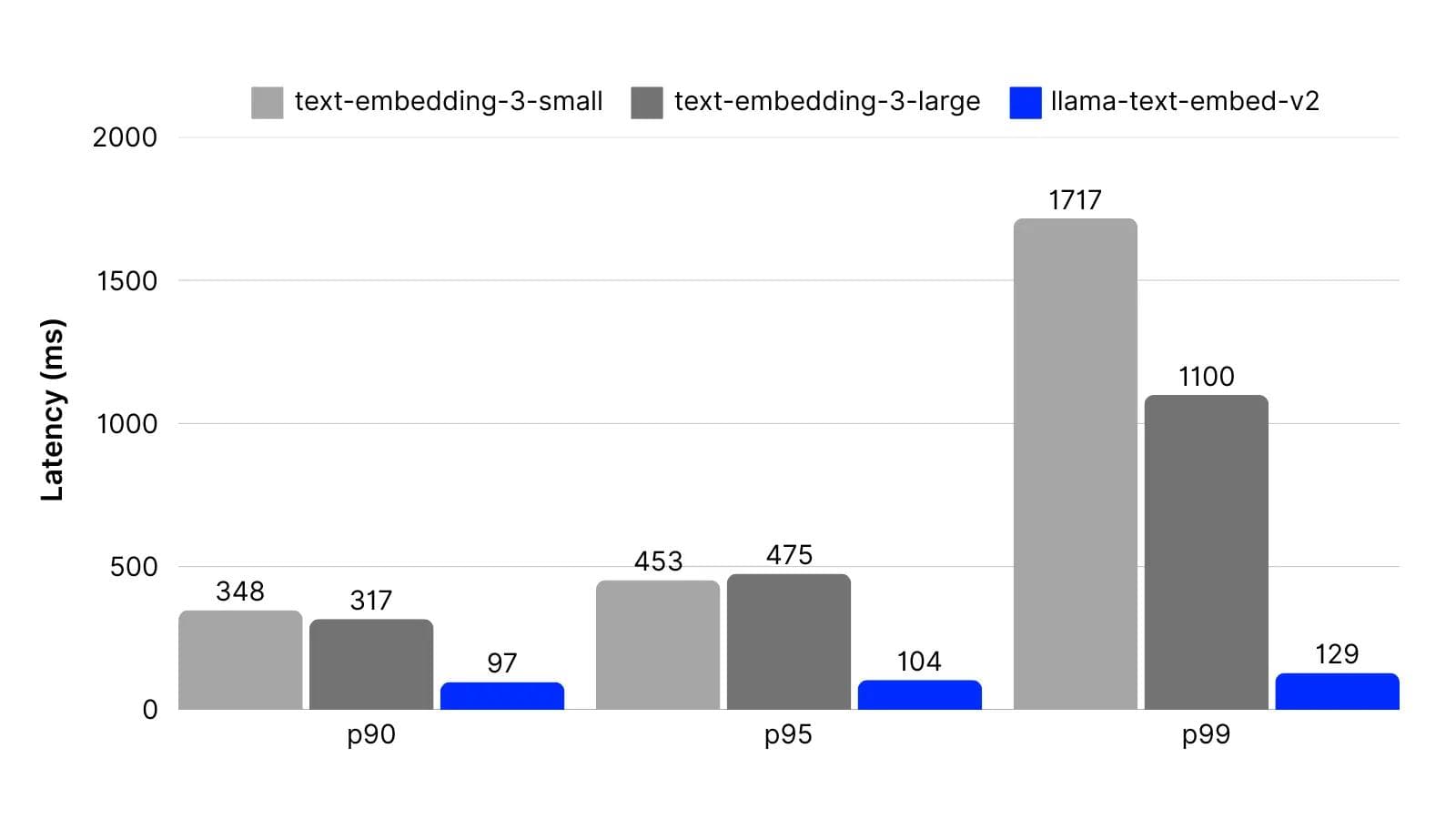
Based on the benchmark results, llama-text-embed-v2 significantly outperforms OpenAI's models.
- P90 latency 90ms: 3.4x faster than OpenAI Small
- P99 latency 129ms: 12x faster than OpenAI Large
The model shows remarkably consistent performance, with a maximum latency of 408ms compared to OpenAI's models which spike to 1420ms (small) and 7716ms (large).
Get started with llama-text-embed-v2
You can experiment with llama-text-embed-v2 free of charge until March 1, after which pricing is set at $0.16/1M tokens with 5M free tokens per month for Starter Tier users. You can access the model through Pinecone’s embed endpoint or with integrated inference, a new capability the manages embedding in reranking in a single API call.
from pinecone import Pinecone
pc = Pinecone(api_key="<API_KEY>")
pc.create_index_from_model(
name="llama-index",
embed={
model="llama-text-embed-v2",
field_map={
"text": "chunk_text" # Field to embed
}
}
)
index = pc.Index("llama-text-index")
data = [
{"id": "1", "chunk_text": "Natural language processing is revolutionizing how we interact with computers"},
{"id": "2", "chunk_text": "Machine learning algorithms can identify patterns in large datasets"},
{"id": "3", "chunk_text": "Deep learning models have achieved remarkable results in computer vision"},
{"id": "4", "chunk_text": "Vector embeddings help computers understand semantic relationships between words"},
{"id": "5", "chunk_text": "Artificial intelligence is transforming industries across the globe"}
]
index.upsert_records(
"ns1",
data
)
response = index.search(
namespace="ns1",
query={
"inputs":{
"text": "how do computers understand semantics?"
},
"top_k": 10
}
)
for r in response['results']['hits']:
print(f"ID: {r['id']} | Score: {r['score']:.3f} | Text: {r['fields']['chunk_text']}")