Building a reliable, curated, and accurate RAG system with Cleanlab and Pinecone
- The Importance of Reliability in RAG Systems
- Setting Up Pinecone
- Using TLM for Document Tagging
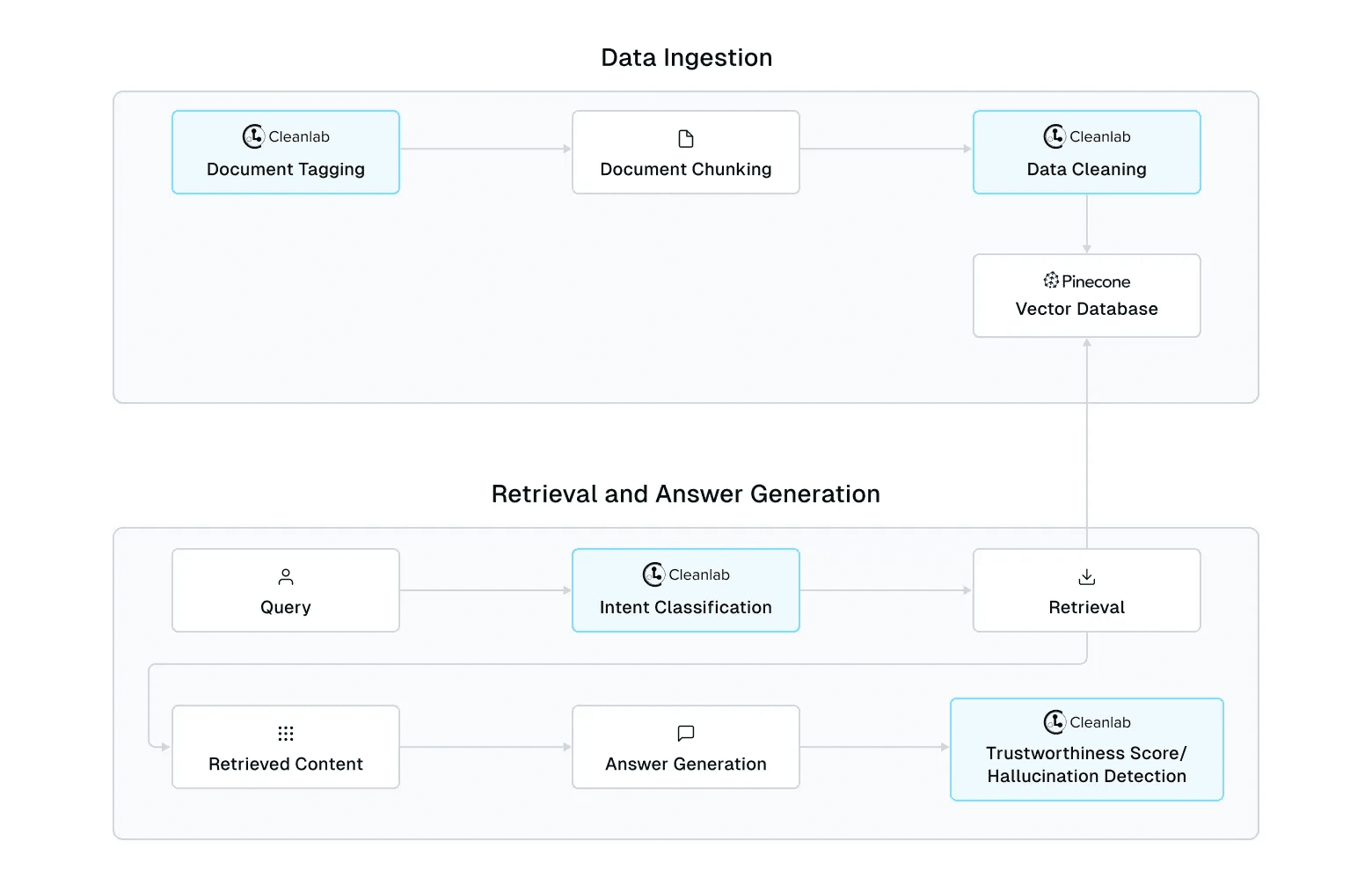
- Creating the RAG Pipeline
- Cleaning and Curating Data with Cleanlab's TLM
- Enhancing Retrieval with Metadata Classification
- Evaluating RAG Outputs with Cleanlab's TLM
- Flagging L ess Trustworthy Responses for Human Review
- Apply Cleanlab's TLM to Existing RAG Prompt/Response Pairs
- Why Cleanlab and Pinecone Work So Well Together
- Conclusion
In today's AI landscape, Retrieval-Augmented Generation (RAG) has emerged as a game-changing technique, combining the power of large language models with external knowledge retrieval. However, the challenge lies in building RAG systems that are not just prototypes but that can actually be deployed to production and be reliable, curated, accurate, and scalable. This tutorial explores how to build such a system using Cleanlab and Pinecone. The code for the tutorial is available in this notebook.
Cleanlab is a tech-enabled AI company supporting enterprises to create highly curated knowledge bases to power their GenAI and Agentic systems, connected to all their data sources. One of the core technologies Cleanlab uses to make GenAI systems work more accurately is the TLM (what this integration and blog is about). Cleanlab's Trustworthy Language Model (TLM) is designed to add trust and reliability to AI model outputs and indicate when it's unsure of an answer, making it ideal for applications where unchecked hallucinations could be problematic. This is especially the case for anyone trying to build generative AI applications in production. Cleanlab's platform enables organizations to deploy reliable AI solutions up to 10× faster than traditional approaches and enables accurate human-in-the-loop customer support escalation, reliable action taking and orchestration when an agent (using TLM) is confident in its the next step, and improved deflection rates with automation (using TLM trustworthiness score).
The Importance of Reliability in RAG Systems
Before we dive into the technical details, let's underscore why building reliable RAG systems is crucial:
- Mitigating Hallucinations: Large language models are prone to generating false or inconsistent information. A reliable RAG system significantly reduces this risk by grounding responses in factual, retrieved information.
- Ensuring Up-to-Date Information: Unlike static models, RAG systems can be easily updated with new information, ensuring responses are current and relevant.
- Enhancing Explainability: With RAG, we can trace responses back to source documents, improving transparency and trust in AI-generated content.
- Protecting Sensitive Information: For policy-adherent and safe AI applications, particularly in fields like healthcare or finance, ensuring accurate and properly curated information is not just important—it's critical.
- Maintaining Brand Reputation: For businesses using AI interfaces, providing reliable information is crucial for maintaining customer trust and brand integrity.
Now let's show the process of building this system using Cleanlab and Pinecone.
Setting Up Pinecone
First, we need to set up our environment to use Pinecone:
import os
import pinecone
from pinecone import ServerlessSpec
# Set up Pinecone API key
if "PINECONE_API_KEY" not in os.environ:
os.environ["PINECONE_API_KEY"] = input("Please enter your Pinecone API key: ")
# Set up Pinecone cloud and region
cloud = os.environ.get("PINECONE_CLOUD") or "aws"
region = os.environ.get("PINECONE_REGION") or "us-east-1"
spec = ServerlessSpec(cloud=cloud, region=region)Using TLM for Document Tagging
One crucial step in building an effective RAG system is properly tagging your documents. Cleanlab's TLM can be used to automatically tag documents with relevant topics, which can later be used for more accurate retrieval. To implement this we first initialize TLM using our Cleanlab API key:
from cleanlab_studio import Studio
key = input("Please enter your Cleanlab API key: ")
studio = Studio(key)
# Instantiate TLM
tlm = studio.TLM()Then we can create the prompt used to tag our documents.
tagging_prompt = """
You are an assistant for tagging text as one of several topics. The available topics are:
1. 'finance': Related to financial matters, budgeting, accounting, investments, lending, or monetary policies.
2. 'hr': Pertaining to Human Resources, including hiring, employee management, benefits, or workplace policies.
3. 'it': Covering Information Technology topics such as software development, network infrastructure, cybersecurity, or tech support.
4. 'product': Dealing with a specific company product, product development, management, features, or lifecycle.
5. 'sales': Involving selling a product, customer acquisition, revenue generation, or sales performance.
If you are not sure which topic to tag the text with, then answer 'unknown'.
Task: Analyze the following text and determine the topic it belongs to. Return the topic as a string.
Now here is the Text to verify:
Text: {text}
Topic:
"""
# ... (code for actually tagging the documents can be found in the tutorial notebook)This process tags each document with a relevant topic and provides a trustworthiness score for each tagging decision. You can then use these tags as metadata when indexing your documents in Pinecone, allowing for more precise filtering during retrieval.
Creating the RAG Pipeline
The core of our system is the PineconeRAGPipeline class. This class handles the creation of the Pinecone index, document chunking, indexing, and searching:
class PineconeRAGPipeline:
def __init__(
self,
model_name: str = "paraphrase-MiniLM-L6-v2",
index_name: str = "document-index",
cloud: str = "aws",
region: str = "us-east-1",
):
self.model = SentenceTransformer(model_name)
self.pc = pinecone.Pinecone(api_key=os.environ.get("PINECONE_API_KEY"))
self.index_name = index_name
# ... (code for the rest of the class can be found in the tutorial notebook)
Cleaning and Curating Data with Cleanlab's TLM
Cleanlab's TLM is used to identify and filter out low-quality document chunks and personally identifiable information (PII):
bad_chunks_prompt = """
I am chunking documents into smaller pieces to create a knowledge base for question-answering systems.
Task: Help me check if the following Text is badly chunked. A badly chunked text is any text that is: full of HTML/XML and other non-language strings or non-english words, has hardly any informative content or missing key information, or text that contains Personally-Identifiable Information (PII) and other sensitive confidential information.
Return 'bad_chunk' if the provided Text is badly chunked, and 'good_chunk' otherwise. Please be as accurate as possible, the world depends on it.
Text: {text}
"""
# PII detection
pii_prompt = """
I am chunking documents into smaller pieces to create a knowledge base for question-answering systems.
Task: Analyze the following text and determine if it has personally identifiable information (PII). PII is information that could be used to identify an individual or is otherwise sensitive. Names, addresses, phone numbers are examples of common PII.
Return 'is_PII' if the text contains PII and 'no_PII' if it does not. Please be as accurate as possible, the world depends on it.
Text: {text}
"""
# ... (code for classifying chunks and detecting PII can be found in the tutorial notebook)
# Delete the identified chunks from the index
rag_pipeline.delete_chunks(chunks_to_delete_ids)Enhancing Retrieval with Metadata Classification
Cleanlab's TLM can also be used for intent classification, which helps in classifying metadata for more accurate retrieval from our RAG system:
intent_classification_prompt = """
Task: Analyze the following question and determine the topic it belongs to. Return the topic as a string.
Now here is the question to verify:
Text: {text}
Topic:
"""
# ... (code for classifying intent and using it for retrieval can be found in the tutorial notebook)Evaluating RAG Outputs with Cleanlab's TLM
Finally, we can use Cleanlab's TLM to evaluate the trustworthiness of RAG outputs:
question = "What were Blackstone's fee-related earnings in the third quarter of 2023?"
# ... (code for retrieving context and generating response can be found in the tutorial notebook)
output = tlm.prompt(prompt)This process helps in identifying potential hallucinations or incorrect answers, adding an extra layer of reliability to our RAG system. Let's look at an example of how this can catch a hallucination:
question = "Can you tell me if these Good's Homestyle Potato Chips support 9 per row in the case?"
# ... (code for retrieving context and generating response can be found in the tutorial notebook)
output = tlm.prompt(prompt)
# Output: {'response': "Yes, the Good's Homestyle Potato Chips support 9 per row in the case, as indicated by the pallet configuration of 72 per pallet (9 x 8).", 'trustworthiness_score': 0.7508270454814128}
# Actual correct information:# '24/case (3 x 6 & 6 on top)'In this example, the model hallucinated an incorrect answer, but the trustworthiness score (0.75) indicates that the response might not be reliable. This demonstrates how Cleanlab's TLM can help identify potential inaccuracies in RAG outputs. Based on this trustworthiness score, we can alter the response to something like: "Based on the provided context, I am unable to accurately answer that question” or flag the response to a human for further review.
Flagging Less Trustworthy Responses for Human Review
One of the key advantages of using Cleanlab's TLM in a RAG system is the ability to identify potentially unreliable responses through trustworthiness scores. You can enhance your RAG system's reliability by implementing contingency plans for responses that fall below a certain trustworthiness threshold.
Here are several ways to handle low-trust responses:
Human Review Pipeline: Route responses with low trustworthiness scores to human experts for verification and correction.
Warning Flags: Automatically append warning messages to responses that fall below the trustworthiness threshold.
Default Fallbacks: Revert to pre-defined baseline answers when confidence is low.
Additional Context: Request more information or context from the user to improve response accuracy.
For example, if we set a trustworthiness threshold of 0.8 since our previous example’s hallucination had a trustworthiness score of 0.75, we might handle a response like this:
threshold = 0.8
if output['trustworthiness_score'] < threshold:
output['response'] = output['response'] + "\\n CAUTION: THIS ANSWER HAS BEEN FLAGGED AS POTENTIALLY UNTRUSTWORTHY"When selecting appropriate trustworthiness thresholds, it's important to:
- Consider relative trustworthiness levels between different responses before looking at absolute scores
- Choose application-specific thresholds based on your use case requirements
- Regularly review and adjust thresholds based on performance
- Consider the criticality of the application domain when setting thresholds
For organizations with sufficient resources, implementing a human review process for low-trust responses can significantly improve response quality. For those with more limited resources, automated warning systems can still provide valuable safeguards against potential misinformation.
This approach to handling low-trust responses adds another layer of reliability to your RAG system, helping to ensure that users are aware when responses might need additional verification or review. For more information on how to choose the appropriate threshold, you can refer to the TLM quickstart tutorial.
Apply Cleanlab's TLM to Existing RAG Prompt/Response Pairs
We can also make use of the get_trustworthiness_score function from Cleanlab's TLM Python API to generate a trustworthiness score for prompt/response pairs that you already have. This can be relevant for a RAG system in which you already have retrieved the context and obtained a response from your LLM but still want to add trust and reliability to these input/output pairs.
prompt = """Based on the following documents, answer the given question.
Documents: We're getting new desks! Specs are here: Staples Model RTG120XLDBL BasePage \\
CollectionModel | Dimensions width = 60.0in height = 48.0in depth = 24.0in Base Color Black \\
Top Color White | Specs SheetsPowered by TCPDF (www.tcpdf.org)
Question: What is the width of the new desks?
"""
response_A = "60 inches"
response_B = "24 inches"
trust_score_A = tlm.get_trustworthiness_score(prompt, response_A)
trust_score_B = tlm.get_trustworthiness_score(prompt, response_B)The trustworthiness score for the prompt/response pair that has the correct response is expectedly much higher (and therefore more trustworthy) than the prompt/response pair with the incorrect response.
Why Cleanlab and Pinecone Work So Well Together
The combination of Cleanlab and Pinecone is suitable for building reliable, curated, and accurate RAG systems:
Data Quality: Cleanlab's TLM excels at identifying and filtering out low-quality data chunks and PII. This ensures that the information stored in Pinecone's vector database is clean, reliable, and policy-adherent. And Cleanlab’s Knowledge Curation platform more generally excels at transforming raw data into high-quality knowledge bases, handling everything from ETL and chunking to identifying and filtering out low-quality data chunks and PII.
Efficient Retrieval: Pinecone's vector database provides fast and accurate similarity search, which is crucial for retrieving relevant information quickly. This efficiency is key to the real-time performance of RAG systems.
Contextual Understanding: Cleanlab's intent classification with TLM helps in understanding the context of queries, which can be used to filter Pinecone's search results more effectively.
Trust and Reliability: Trustworthiness scores obtained with TLM for RAG outputs provide an additional layer of confidence in the system's responses. This is particularly important in applications where the accuracy of information is critical.
Scalability: Both Cleanlab and Pinecone are designed to handle large-scale data, making this combination suitable for enterprise-level RAG applications. As the application's use grows, this system can be easily scaled to accommodate increased demand. Trustworthiness scores also enable efficient human-in-the-loop AI data processing workflows.
Conclusion
Building a reliable, curated, accurate, and scalable RAG system is not just about improving AI performance — it's about creating AI systems that can be trusted and relied upon in real-world applications. The combination of Cleanlab's TLM and Pinecone's vector database addresses the key challenges in RAG system development:
- Ensuring high-quality data for chunking and retrieval
- Accurate and context-aware information retrieval
- Trustworthy and verifiable AI-generated responses to prevent hallucinations and flag responses for human review
- Scalability to handle growing application demands and robustness to varying datasets
By leveraging these tools together, we can build RAG systems that not only retrieve information efficiently but also ensure the quality and trustworthiness of the information provided. This approach sets a new standard for building reliable AI systems that can be deployed with confidence in critical domains such as healthcare, finance, legal services, and more.
As AI continues to integrate into various aspects of our lives and businesses, the importance of reliability, trustworthiness, and scalability in these systems cannot be overstated. With Cleanlab and Pinecone, we have a powerful approach to meet these crucial requirements and push the boundaries of what's possible with RAG systems. For the full code, please refer to this notebook.
For more information on Cleanlab benchmarks with TLM, refer to the links below:
https://cleanlab.ai/blog/rag-tlm-hallucination-benchmarking/
https://cleanlab.ai/blog/trustworthy-language-model/
What Cleanlab does for you:
Cleanlab is an AI infrastructure company for enterprises building GenAI systems. Cleanlab transforms your raw, messy enterprise data into a single, high-quality AI knowledge base, handling everything from ETL and chunking to de-duplication and curation. Cleanlab’s team of forward deployed engineers customize their technology to fit your needs. Build GenAI, RAG, and agentic systems that are policy-adherent, safe, and highly accurate—deployed 10× faster. Use cases include customer support automation, “chat with my docs” product support, and enterprise search. Unlock reliable AI solutions powered by Cleanlab’s AI infrastructure.