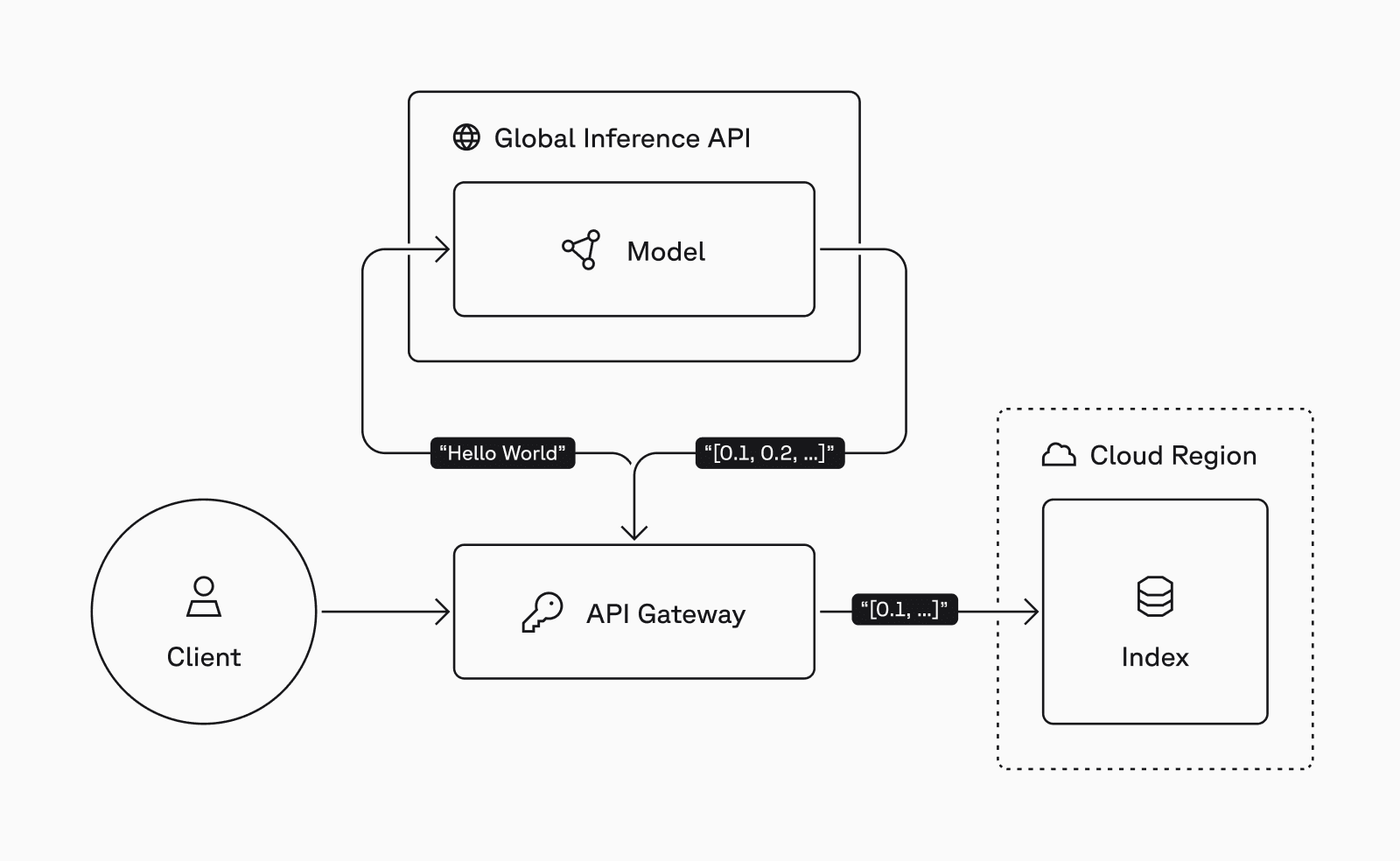
Introducing Pinecone Inference, an API that provides easy and low-latency access to embedding and reranking models hosted on Pinecone’s infrastructure. Inference — alongside our vector database — makes Pinecone a “one-stop shop” for embedding, managing, and retrieving vector data through a single API. This lets you build knowledgeable AI applications faster, with less complexity and fewer tools to manage.
Inference is in public preview and currently supports the multilingual-e5-large model, with others coming soon.
Embed, manage, and query your data with a single API
Choosing a suitable embedding model can be time-consuming: You must choose from over two hundred based on multiple factors such as modality, subject domain, and deployment mode, and then you must implement a separate inference service into your application workflow. You’d probably rather spend your efforts prototyping and shipping knowledgeable AI applications.
We chose to start with ‘multilingual-e5-large’ because it’s small, open source, natively multilingual, and performs well on benchmarks across languages. Learn more in our deep dive on e5, including an example notebook for building a search application with Inference.
from pinecone import Pinecone
pc = Pinecone("API-KEY")
pc.inference.embed(
model="multilingual-e5-large",
inputs=[
"The quick brown fox jumped over the lazy dog"
],
parameters={
"input_type": "passage", # passage or query
"truncate": "END" # END or NONE, if NONE raises error
}
)Note: multilingual-e5-large leverages asymmetric embeddings for retrieval. You can set the input_type to either ‘passage’ or ‘query’.
While Inference can help accelerate your AI development, Pinecone also supports dense embeddings with up to 20k dimensions from any embedding model or model provider. Choose the model that works best for your workload, regardless of source.
Try Inference today and simplify your workflow
Pinecone Inference is now available in public preview for all users. Starter and Enterprise users pay $0.08 per million tokens, while those on the Starter (free) plan have access to 5 million monthly tokens. We will add reranking and more embedding models in the coming months. Here is a quick resource on how to generate embeddings. Explore our interactive model gallery, and start building with Inference today.