Launch Week is here at Pinecone! Every day this week, we're rolling out new features to better support you in building accurate and performant AI applications at scale in production. This blog will serve as your go-to hub for all announcements, updated daily with the latest reveals. Stay tuned, and follow us on socials to keep up with the action!
Day 1: Optimizing Pinecone for agents (and more)
Agentic workloads differ from traditional search and recommendation systems, involving millions of small namespaces with bursty, unpredictable query patterns.
Over the past year, we’ve evolved our serverless architecture to tackle these challenges with innovations across both our query and write paths, including:
- Adaptive indexing using log-structured merge trees
- Support for millions of namespaces per index—without sacrificing performance or cost
We’ve also boosted search and recommendation performance with:
- Enhanced metadata filtering
- High-performance sparse indexing for keyword search
- Automatic replication at high QPS (w/ provisioned capacity options coming soon), and more

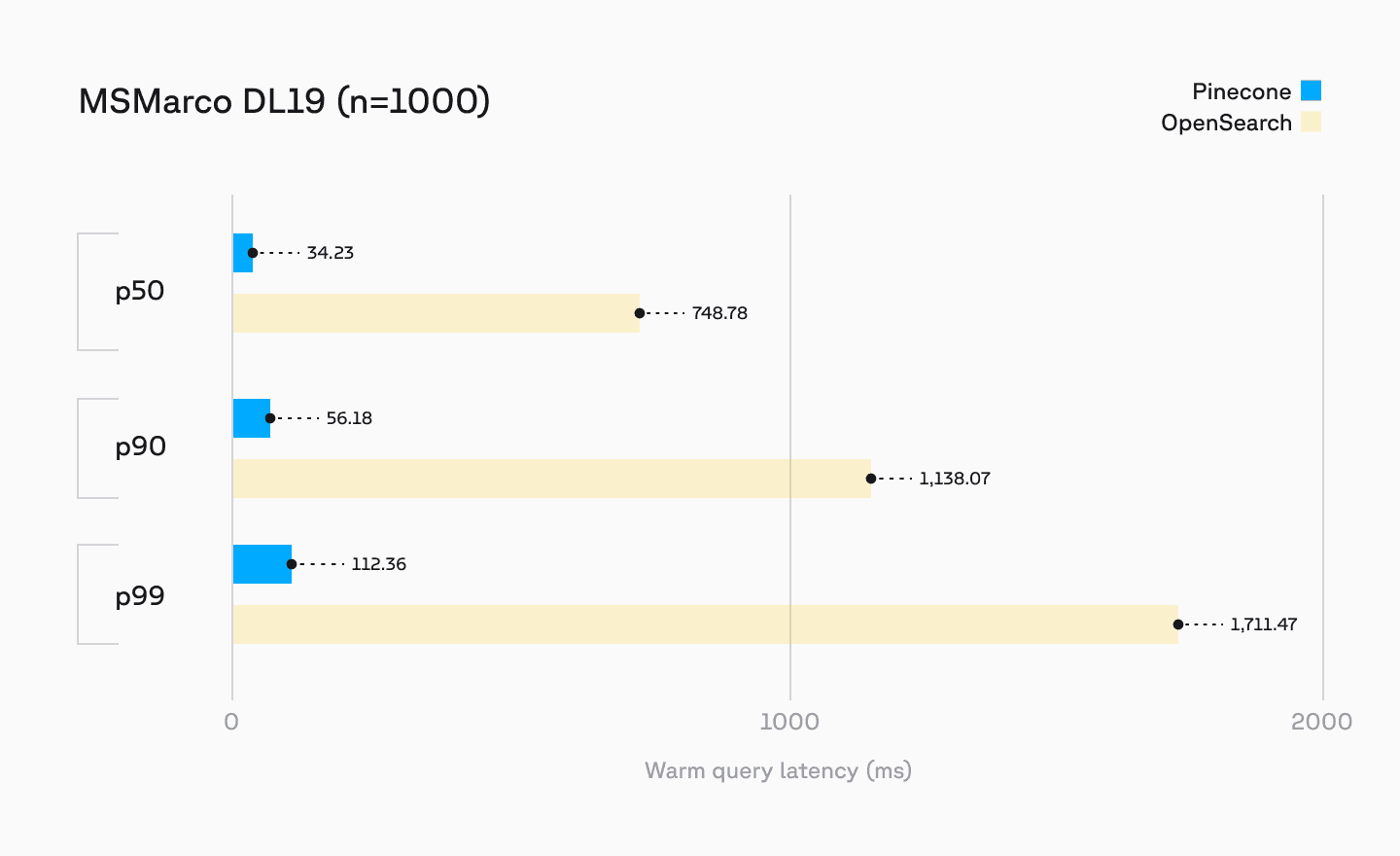
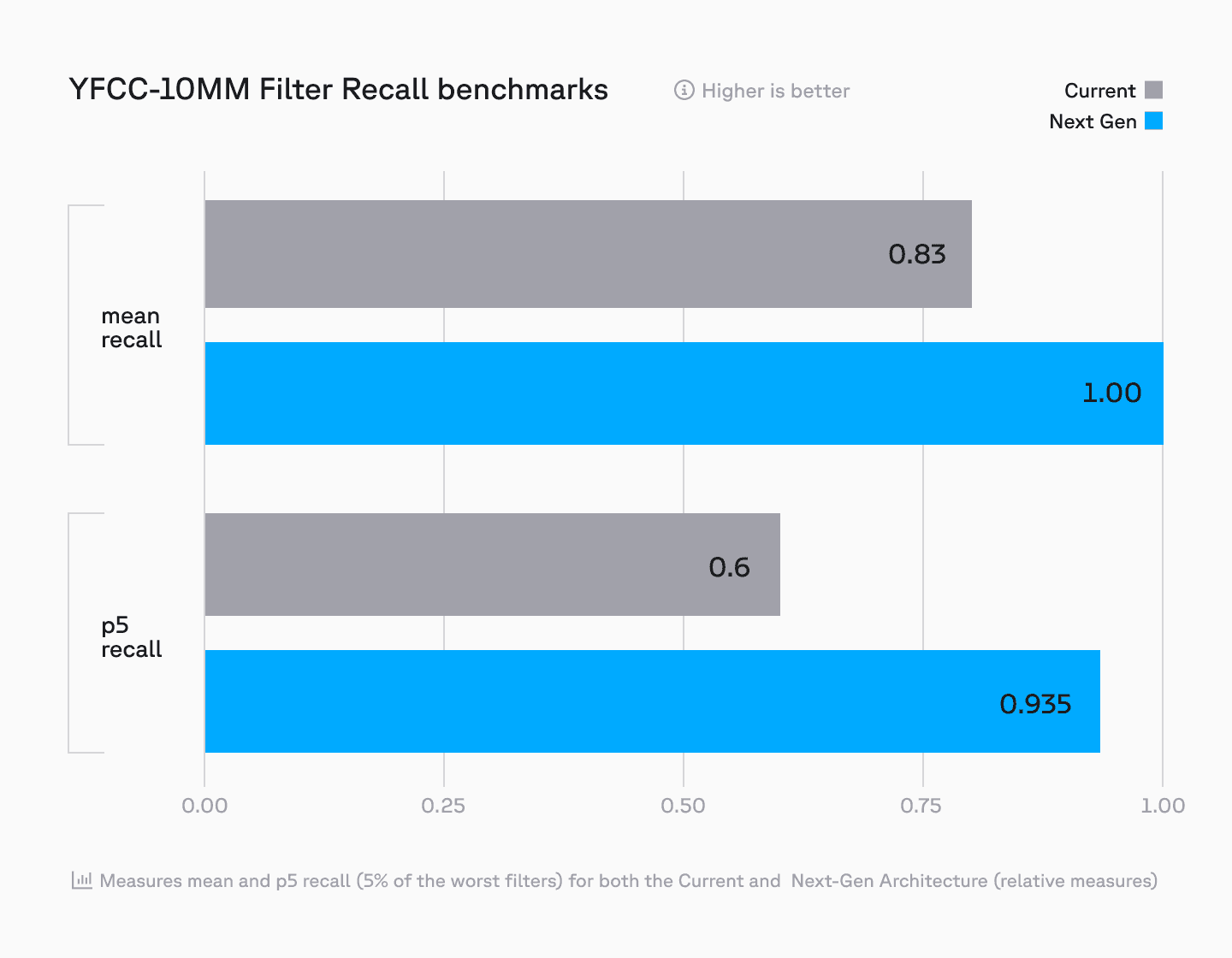
Learn more about these performance optimizations in our deep dive by CEO Edo Liberty and Principal Product Manager Nathan Cordeiro.
Day 2: Backup and Restore APIs
Until today, serverless backups were only accessible through the Pinecone console. Now, with the new Backup and Restore APIs, you can programmatically manage backups for serverless indexes—bringing greater flexibility, automation, and control to your data protection strategy.
Available to all Standard and Enterprise users, these APIs help organizations:
- Safeguard critical data against system failures and accidental deletions
- Ensure business continuity by restoring indexes to known good states
- Meet compliance requirements (e.g., SOC 2 audits) with structured backup policies

New API Endpoints:
This release introduces six new endpoints to programmatically create and manage backups:
- Create backup from an index
- List backups for an index
- List all backups
- Describe backup
- Delete backup
- Create index from a backup
What’s next?
Backup and Restore APIs are now available in public preview. We’re continuing to build even more powerful backup capabilities, including:
- In-place index reversion for faster rollbacks
- Automated backup scheduling for hands-free data protection
- Export to cloud storage for external archiving
- Cross-cloud and cross-region restoration for ultimate flexibility
See our documentation to learn more (backup guide and restore guide), and start building today.
Day 3: Admin API and Service Accounts
We are excited to announce the public preview of the Pinecone Admin API. This new suite of API endpoints enables you and your team to programmatically create and manage high-level administrative resources within your organization. In this first release, you can programmatically create and manage projects and API keys. The Admin API will continue to be expanded in future releases with endpoints for creating and managing storage integrations, project members and roles, encryption keys, and more.

Previously, the creation of API keys and projects was only available through the console, and access to these actions was based on project and organization roles. Since API keys are project-specific and limited to actions within those projects, these high-level administrative actions couldn’t be taken via API. To address this gap, we are introducing service accounts in Pinecone. Starting today, you can create and manage service accounts in the console.
Service Accounts provide their own set of credentials that can be used to authenticate, and represent a set of roles and permissions rather than a specific user. With Service Accounts, you can now take these administrative actions directly via API, and incorporate these actions into your organization’s testing suite. In coming releases, service accounts will be expanded to facilitate access to the data plane and control plane as well.
Today, the Admin API is available for organizations on the Enterprise plan. Support for the Admin API in the Pinecone Terraform Provider will be available in the coming months. To get started, take a look at the documentation or head straight to the console to create a service account.
Day 4: Audit Logs
Audit Logs are now available in public preview, with Amazon S3 as the first destination. Giving you detailed visibility into user, service account, and API activities across your Pinecone organization, this self-serve capability enhances security monitoring and compliance management.
With Audit Logs, organizations can track critical operations including:
- Resource management (projects, indexes, backups)
- Access management changes (API keys, user roles, project memberships)
- Security configurations (private endpoints, customer-managed encryption keys)
Each audit event captures essential information including the principal (e.g. who performed the action), the action itself, the affected resource, and associated metadata like IP addresses and timestamps. Events are sent every 30 minutes to a user-provided Amazon S3 bucket, providing a comprehensive audit trail for security and compliance.

Looking ahead, we're working on additional capabilities including:
- Support for Google Cloud Storage and Azure Blob Storage
- A native UI in the Pinecone Console
- Data plane event logging
- Integration with popular SIEM platforms
Audit Logs are now available in public preview for all Enterprise users. Check out our documentation to learn more and visit the console to enable Audit Logs for your organization today.
Day 5: Dark Mode
We’re wrapping up launch week with one of our most requested features- dark mode! Now live across our website, docs, and console.
Happy building!
